The Global Lexicostatistical
Database: Downloads
The
GLBD Experimental Tree-Building Procedures: Some Preliminary Results
Mostly as a rough preview for more important things to come, this page
hosts some of the classificatory results, achieved within the GLD based on (1)
application of standard comparative-historical procedure to relatively small
(«level 1») databases; (2) attempts to replace potentially subjective
historical analysis with «objective» computerized procedures; (3) skipping
detailed analysis of individual wordlists and creating a preliminary rough
sketch of how one of the highest levels of the GLD could look like in the
future.
1. «Regular» Trees
The GLD currently offers its users the possibility to create
genealogical trees in on-line mode based on a whole variety of parameters (see A Quick Tutorial for more detailed information). The default tree is, however, assumed to be
the one based on either «Fixed rate» (based on Sergei Starostin's revision of
the Swadesh formula, with the rate of replacement per millennium = 0.05%) or
«Variable rate» (based on the same formula, but with a variable rate, dependent
on individual stability indexes of different Swadesh items); the two are
usually very close. The table below allows to quickly browse through the
«official» trees — including glottochronological dates of separation — for all
of the language groups currently uploaded on the main GLD site.
|
Language group |
Fixed rate tree |
Variable rate tree |
Language group |
Fixed rate tree |
Variable rate tree |
|
Ekoid |
|
|
North Khoisan |
|
|
|
Nakh |
|
|
Ob-Ugrian |
|
|
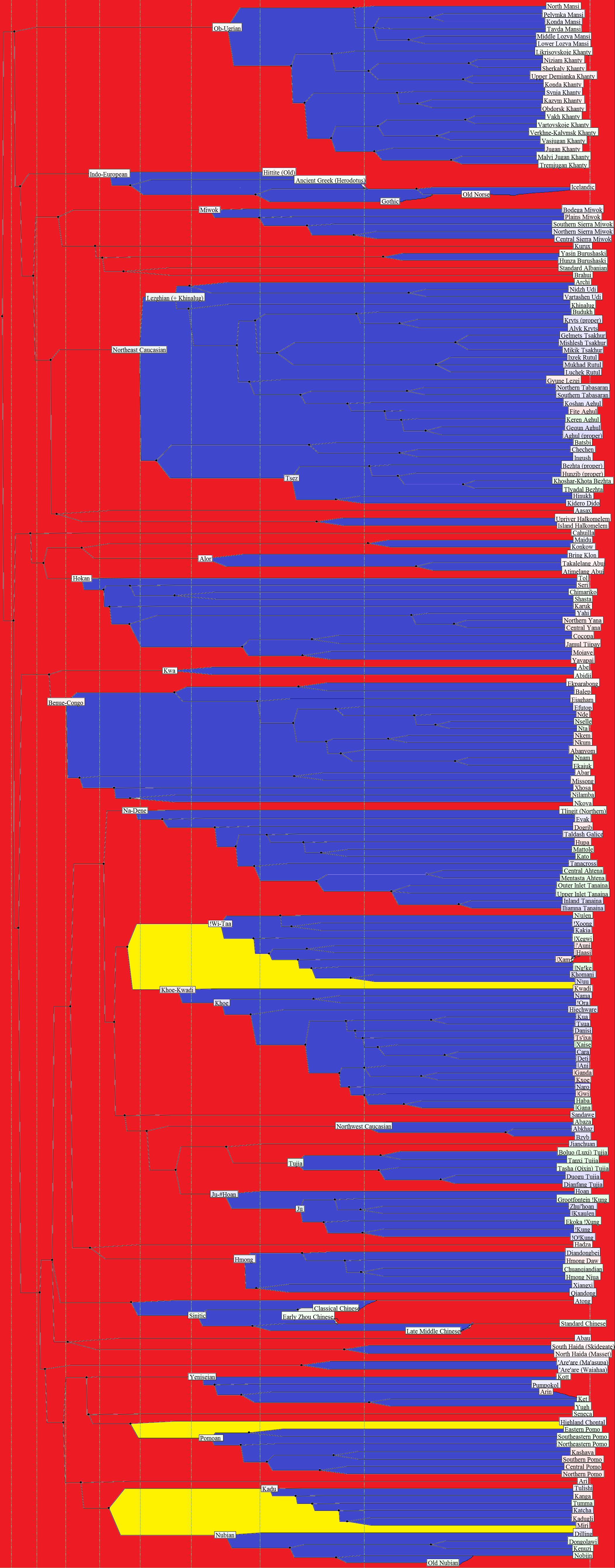
2. The «Objectively Generated» Tree of Phonetic Similarity
This particular tree is constructed on principles that are similar to
the much larger «ASJP
World Language Tree of Lexical Similarity» (the latter utilizes a slightly
more complex algorithm and includes about 100 times as many languages, although,
on the other hand, it only operates on 40-item wordlists of generally more
dubious quality). It includes data from all
the languages entered into the GLD (minus some of the latest additions; new
versions should be expected every few months), treated as follows:
a. Etymologically based cognation indexes, supplied by wordlist
compilers, have been removed;
b. New cognation indexes are generated automatically by means of an
algorithm that assumes «cognation» based on phonetic
similarity of the words compared. Phonetic
similarity is, in this case, defined as «the first and the second consonant of the
roots of the compared words respectively belong to the same consonantal
classes» (information on consonantal classes is contained in the StarLing
file sound.dbf, whose structure can be seen here).
c. A lexicostatistical matrix and genealogical tree are constructed,
based on new «cognation» indexes with the application of the «Variable rate»
formula.
Click here
to view the latest version (01.14.2013) of The «Objectively Generated» Tree of Phonetic Similarity.
{kind=link}
Older
versions: 10.19.2011, 07.31.2011.
{kind=link}
{kind=link}
Colors between nodes are to be understood as follows:
blue = the computer has
correctly identified a language family or at least a subset of such a family
(although its internal structure may still have been identified with errors).
Such results are positive;
yellow = the computer has
identified all or part of a «controversial» family that has been hypothesized
by at least some linguists on a serious level, but has not found mass
acceptance. Such results are relevant,
but inconclusive;
red = the established
link (as a rule, based on a minimal number of «cognates» that is
indistinguishable from chance) reflects a currently unprovable or vaguely
guessed connection at a deep level. Such results are irrelevant.
3.
Preliminary Genealogical Tree For Eurasia (based on 50-item wordlists)
This tree can be viewed as a very rough, sketchy «shortcut» towards the
ultimate goal of the GLD project. It has been built based on manual cognate indexation of 50-item
wordlists, created for more than 150 low-level proto-languages (such as Proto-Germanic,
Proto-Turkic, Proto-Ethiosemitic, Proto-Nakh, etc.) and language isolates of
Eurasia. The main body of the database was put together by G. Starostin, with
helpful input from A. Dybo, A. Kassian, M. Zhivlov, and other colleagues at the
Center for Comparative Linguistics.
Cognates were identified, where possible, based on known phonetic
correspondences. For poorly studied families as well as macrofamily levels, basic phonetic resemblance (determined
by more or less the same criteria that are used for the «objectively
generated» tree) has been used instead of regular correspondences. All of the
comparisons have been done based on a «step-by-step» cladistic approach, as
described in the GLD paper «Preliminary
lexicostatistics».
Click here to view the latest version
(07.31.2011) of The Preliminary Genealogical Tree For Eurasia (long variant).
{kind=link}
Click here to view the latest version
(07.31.2011) of The Preliminary Genealogical Tree For Eurasia (short variant).
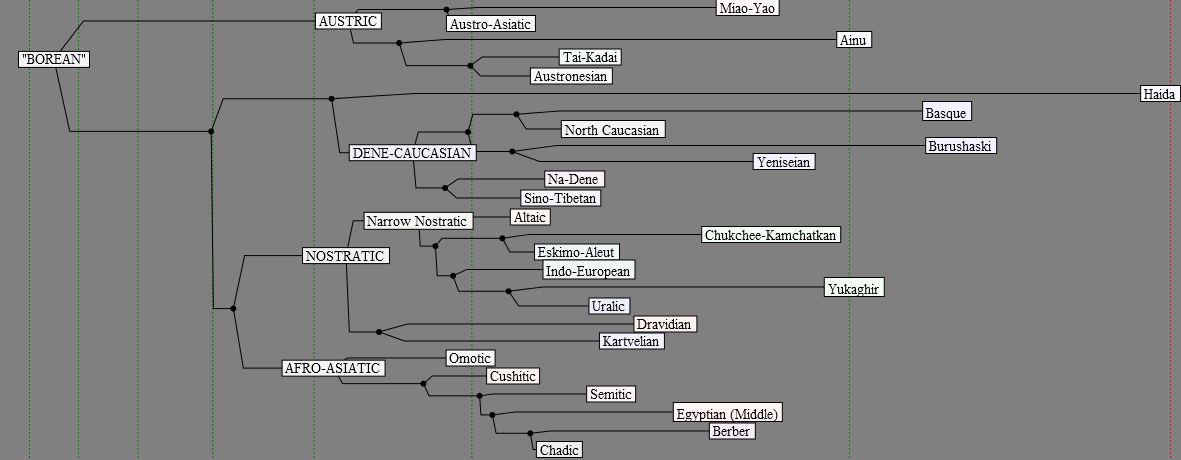{kind=link}
Click here to see the data (without cognation
indexes) in Excel form (WARNING:
Many of the reconstructions are highly preliminary. Please do not quote
anything from this file without consulting us at gstarst@rinet.ru).
BACK TO MAIN PAGE DATABASE
LIST RUSSIAN VERSION
© 2011 George Starostin (site design, data
input coordination)
© 2011 Phil Krylov (programming, technical
support)